SUTRA vs LLMS across non-English Languages
May 1, 2024

Benchmarking SUTRA performance against leading general and language-specific models.
In terms of language model performance, the Metric for Measuring Language Understanding (MMLU) is the core benchmark that measures the nuanced capabilities of a language model to process and understand text.
To illustrate the robustness and efficiency of the SUTRA model, we conducted a thorough comparison of its MMLU scores with those of widely recognized general models such as GPT-4 and Llama3, in addition to language-specific models including HyperClovaX and Rakuten 7B, and many more.
The findings from our analysis underscore that SUTRA not only maintains top performance against large scale models like GPT-4, but also beats models that were built on additional data sets in single languages. The detailed assessment through the MMLU framework provides us with essential insights, affirming that SUTRA is indeed engineered to deliver superior performance across the linguistic spectrum, and further confirms our approach to building multilingual and cost-efficient generative AI models that excel in 50+ languages.
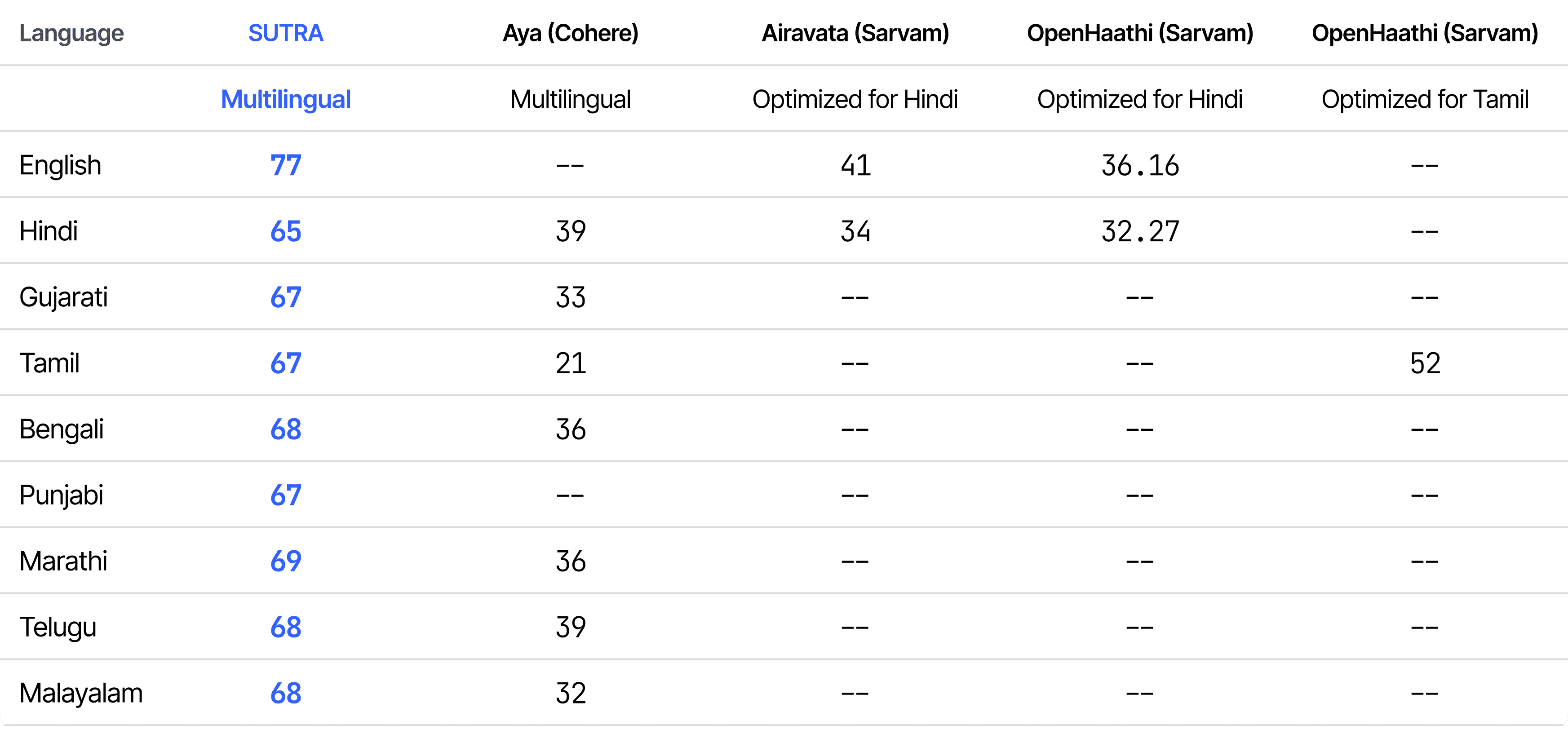
Indian Languages
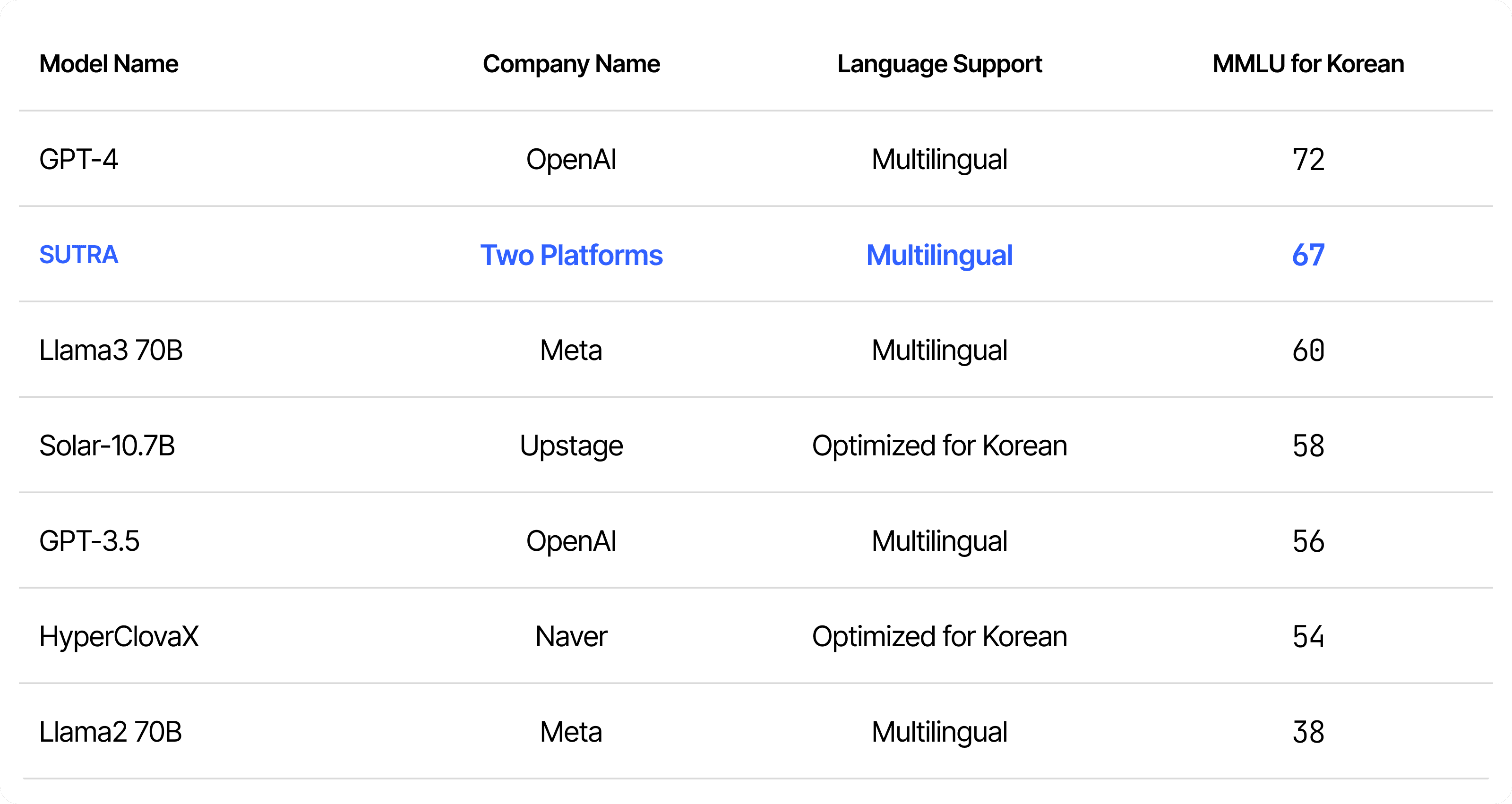
Korean
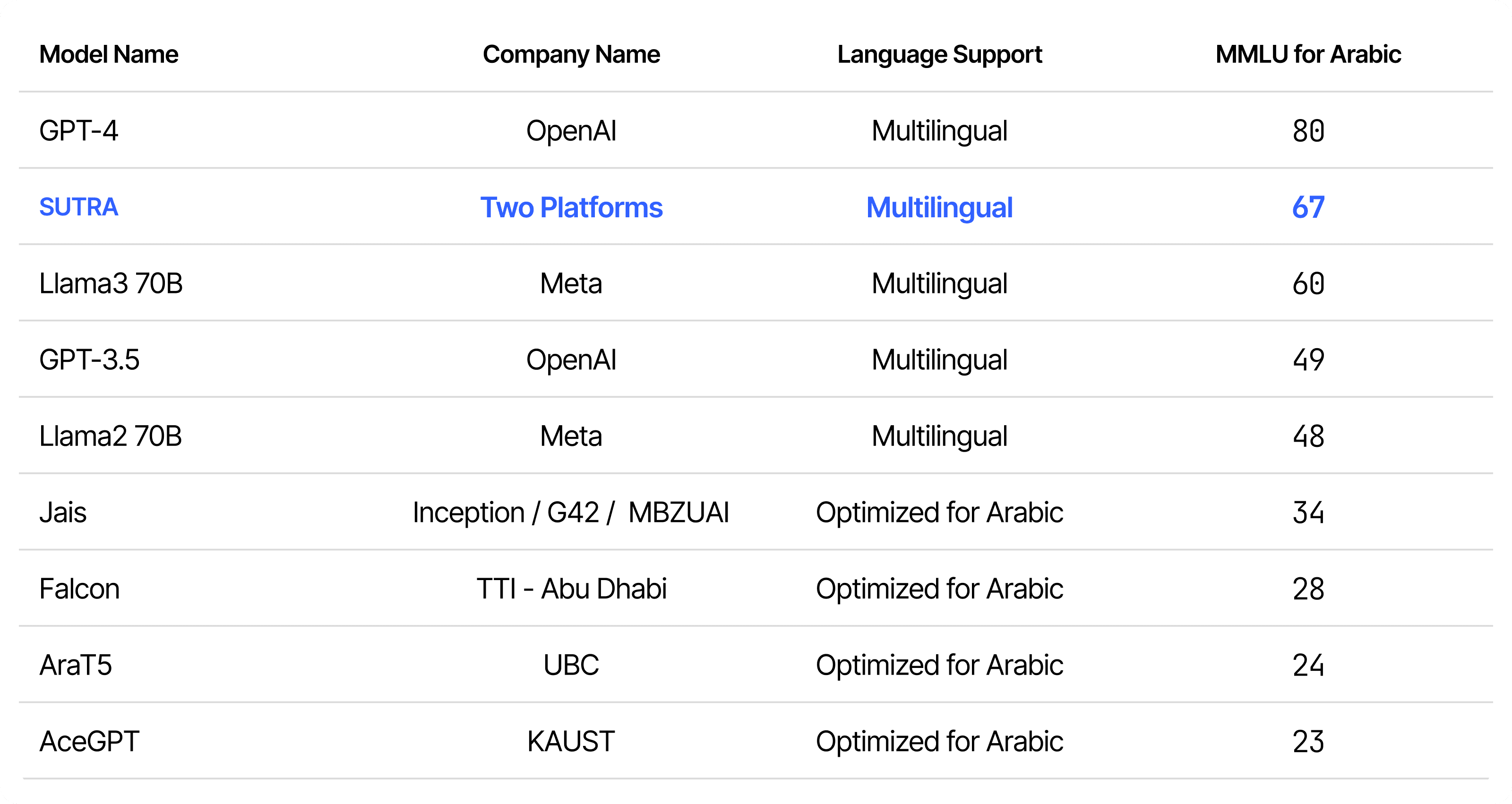
Arabic
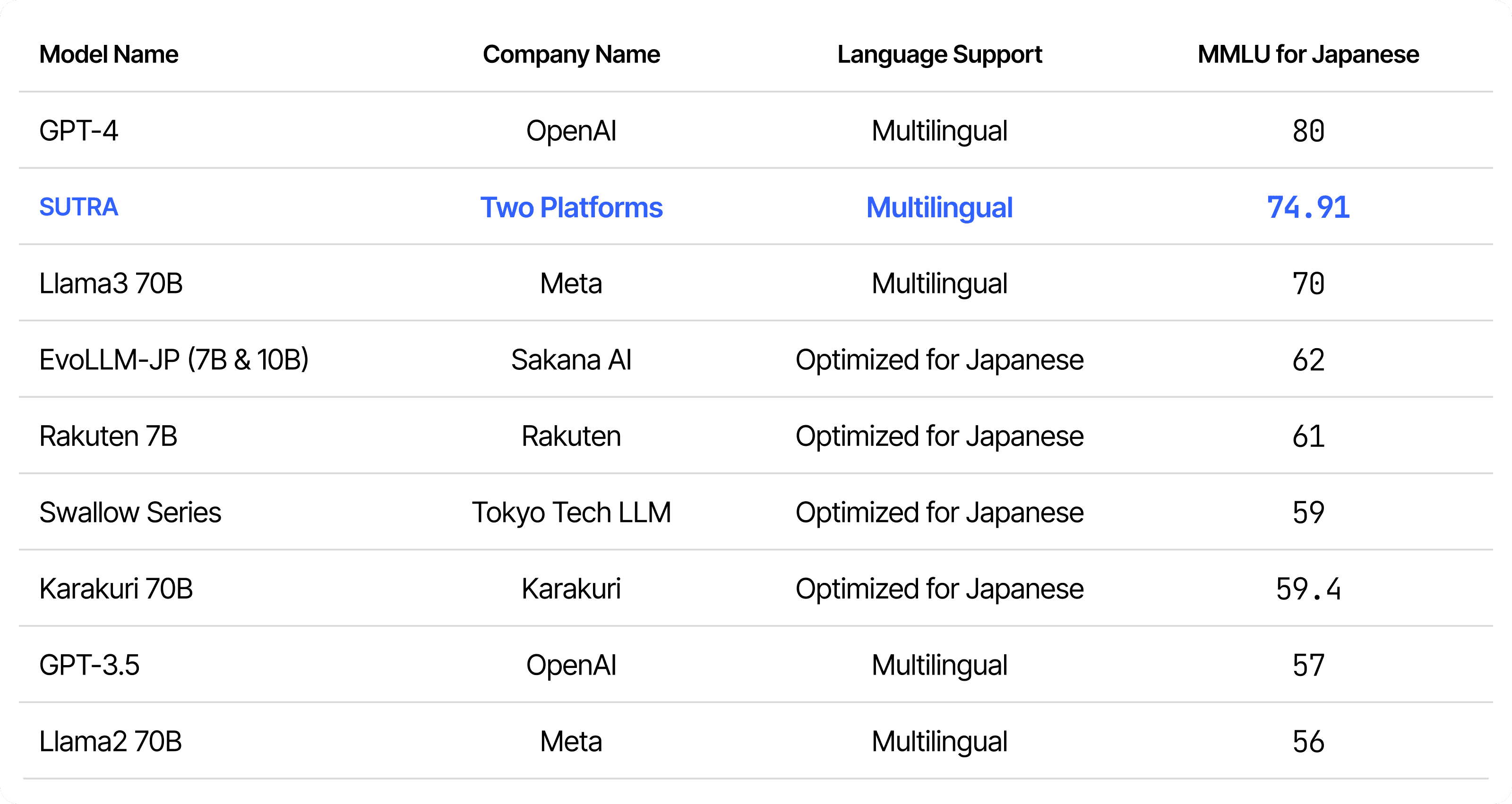
Japanese
Research @ TWO
Recent Posts


