Understanding SUTRA's Multilingual Tokenizer
May 23, 2024
SUTRA’s multilingual tokenizer significantly reduces the cost and computational burden of LLMs by efficiently handling diverse languages with a balanced vocabulary. This breakthrough approach ensures better performance, especially for non-English languages, making multilingual models more accessible and cost-effective.
Three things set SUTRA apart: a dual transformer multilingual architecture that decouples concept learning from language learning, proprietary multilingual and multi-turn user-to-AI conversational data, and a cost-efficient multilingual tokenizer. In this article, we will dive deep into SUTRA's innovative multilingual tokenizer to understand why it is a breakthrough technology with significant impact.
As LLMs continue to expand their reach and applications, the need for multilingual support has become increasingly important. However, handling multiple languages with varying linguistic structures and vocabularies can be a significant challenge for traditional tokenization methods. Efficient tokenizers which can handle a wide range of languages and scripts, are crucial for building effective multilingual LLMs. These tokenizers can learn to represent text from different languages using a shared vocabulary of subword units, enabling the LLM to process and generate text in multiple languages with a single model.
What are Tokenizers?
Tokenizers are algorithms that break down text into smaller units called tokens, which can be words, subwords, or even individual characters. This process of tokenization is a fundamental step in natural language processing (NLP) pipelines, as it converts the raw text input into a numerical representation that can be processed by the LLM's neural network architecture. The choice of tokenization method can significantly impact the performance, efficiency, and capabilities of LLMs. These tokenizers can learn to represent text from different languages using a shared vocabulary of subword units, enabling the LLM to process and generate text in multiple languages with a single model.
Although English-specific tokenizers can generate text in non-English languages, they fail to capture language-specific nuances and are highly inefficient, particularly for non-Romanized languages. For Indian languages like Hindi, Gujarati, and Tamil, tokenizers from leading LLMs such as Llama-2, Mistral, and GPT-4 consume 4.5 to 8 times more tokens compared to English.
The Importance of Efficient Tokenizers for Multilingual Applications
Models like GPT-3.5, Mixtral, and Llama exhibit a significant English bias in their vocabulary, with 90% of tokens derived from a single language. This focus on English leads to inefficiencies and loss of semantic meaning when representing characters from different languages. Due to the very fine granularity, these tokenizers and models struggle to capture semantic meaning effectively. Typically, end consumers are charged based on the input and output token count for LLM inference. This means generating a sentence in Hindi (or other non-English languages) costs users approximately 5X more than it would in English.
Efficient tokenizers can help reduce the overall computational and memory requirements of multilingual LLMs, making them more accessible and cost-effective for a broader range of applications and users. By compressing text more effectively and balancing the vocabulary size, these tokenizers can enable smaller and more efficient LLM architectures while maintaining high performance across multiple languages.
SUTRA’s Tokenizer
One of the primary reasons other models are slow and inefficient in non-English languages is due to their tokenizers, which have vocabularies primarily focused on English. Bilingual models often extend this vocabulary to include other languages, which can hamper performance in English. In contrast, SUTRA's vocabulary is trained with balanced data from multiple languages, leading to an efficient token distribution across languages.
Tokenizer Vocabulary Language Distribution for Leading LLMs
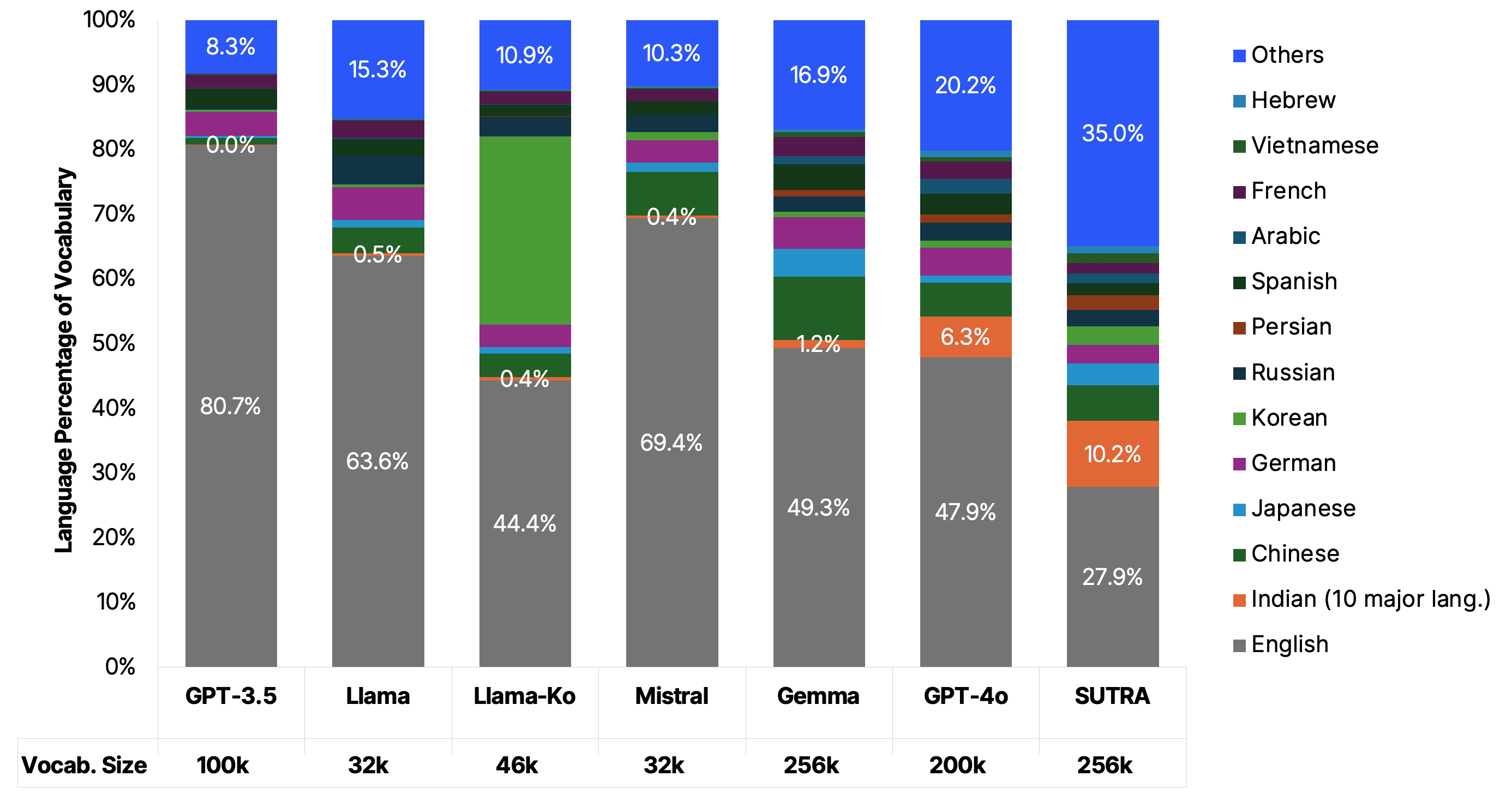
The above plot was generated by classifying tokens from vocabulary and computing histogram over language distribution. Tokens from major Indian languages like Hindi, Gujarati, Tamil, Bengali, Marathi, Urdu, Malayalam, Telugu, Punjabi and Kannada were grouped together as Indian languages.
Our approach involves training a Sentence Piece model based tokenizer with uniform sampling from a wide range of languages using a curated and balanced dataset. SUTRA’s tokenizer has a significantly larger vocabulary, allowing it to efficiently represent multiple languages simultaneously. By avoiding an excessive English bias and maintaining a reasonable level of granularity, our tokenizer and model can better preserve semantic meaning across different languages. Text generated with our tokenizers lead to 80% to 200% reduction in overall tokens consumed across languages, which is critical for bringing down the cost of inferencing when deploying these models for cost-sensitive use-cases.
The example below shows comparison of tokenizers of SUTRA and other leading LLMs. SUTRA tokenizer consumes less tokens across languages and is more efficient than tokenizers from leading models like Llama (from Meta), Gemma (from Google) and GPT-3.5, GPT-4 and even GPT-4o (from OpenAI).

When tokenizing a sentence in Tamil, note how SUTRA is able to split the sentence into sub-words effectively.

This means that each word-like concept is mapped to a richer embedding representation. Tokenizing a language like Tamil effectively means that the subsequent LLM can attend over a larger context window, and reason with elements which are more meaningful. By contrast, other tokenizers need to represent the Tamil sentence using multiple tokens per character, meaning that a single sub-word may have ~8 tokens instead of just 1. The meaning and relationship between these sub-character representations may be lost and is more difficult and costly, and slower to propagage through the LLM due to its auto-regressive nature. Having a better token representation results in superior answers from the LLM, as well as a significantly lower cost when using SUTRA models, compared to other models with inefficient tokenizers.
Research @ Numeric
Recent Posts

ONE, TWO, ... We are NUMERIC.

Distilling... is our Level 2 Game Plan

AI Agents - They Don’t Just Help, They Hustle